Skewness
In probability theory and statistics, skewness is a measure of the asymmetry of the probability distribution of a real-valued random variable. The skewness value can be positive or negative, or even undefined. Qualitatively, a negative skew indicates that the tail on the left side of the probability density function is longer than the right side and the bulk of the values (possibly including the median) lie to the right of the mean. A positive skew indicates that the tail on the right side is longer than the left side and the bulk of the values lie to the left of the mean. A zero value indicates that the values are relatively evenly distributed on both sides of the mean, typically but not necessarily implying a symmetric distribution.
Contents |
Introduction
Consider the distribution on the figure. The bars on the right side of the distribution taper differently than the bars on the left side. These tapering sides are called tails, and they provide a visual means for determining which of the two kinds of skewness a distribution has:
- negative skew: The left tail is longer; the mass of the distribution is concentrated on the right of the figure. It has relatively few low values. The distribution is said to be left-skewed or "skewed to the left".[1] Example (observations): 1,1000,1001,1002,1003
- positive skew: The right tail is longer; the mass of the distribution is concentrated on the left of the figure. It has relatively few high values. The distribution is said to be right-skewed or "skewed to the right".[1] Example (observations): 1,2,3,4,100.
If the distribution is symmetric then the mean = median and there is zero skewness. (If, in addition, the distribution is unimodal, then the mean = median = mode.) This is the case of a coin toss or the series 1,2,3,4,... Note, however, that the converse is not true in general, i.e. zero skewness does not imply that the mean = median.
"Many textbooks," a 2005 article points out, "teach a rule of thumb stating that the mean is right of the median under right skew, and left of the median under left skew. [But] this rule fails with surprising frequency. It can fail in multimodal distributions, or in distributions where one tail is long but the other is heavy. Most commonly, though, the rule fails in discrete distributions where the areas to the left and right of the median are not equal. Such distributions not only contradict the textbook relationship between mean, median, and skew, they also contradict the textbook interpretation of the median."[2]
Definition
The skewness of a random variable X is the third standardized moment, denoted γ1 and defined as
![\gamma_1 = \operatorname{E}\Big[\big(\tfrac{X-\mu}{\sigma}\big)^{\!3}\, \Big]
= \frac{\mu_3}{\sigma^3}
= \frac{\operatorname{E}\big[(X-\mu)^3\big]}{\ \ \ ( \operatorname{E}\big[ (X-\mu)^2 \big] )^{3/2}}
= \frac{\kappa_3}{\kappa_2^{3/2}}\ ,](/2012-wikipedia_en_all_nopic_01_2012/I/c6a46c71c9e5821f51e7b2c2e89b0be1.png)
where μ3 is the third moment about the mean μ, σ is the standard deviation, and E is the expectation operator. The last equality expresses skewness in terms of the ratio of the third cumulant κ3 and the 1.5th power of the second cumulant κ2. This is analogous to the definition of kurtosis as the fourth cumulant normalized by the square of the second cumulant.
The skewness is also sometimes denoted Skew[X].
The formula expressing skewness in terms of the non-central moment E[X3] can be expressed by expanding the previous formula,
![\gamma_1
= \operatorname{E}\bigg[\Big(\frac{X-\mu}{\sigma}\Big)^{\!3} \,\bigg]
= \frac{\operatorname{E}[X^3] - 3\mu\operatorname E[X^2] %2B 3\mu^2\operatorname E[X] - \mu^3}{\sigma^3}
= \frac{\operatorname{E}[X^3] - 3\mu\operatorname E[X^2] %2B 2\mu^3}{\sigma^3}\ .](/2012-wikipedia_en_all_nopic_01_2012/I/50cb221d5fdf930030874e27028cf7e1.png)
Sample skewness
For a sample of n values the sample skewness is
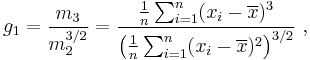
where 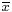 is the sample mean, m3 is the sample third central moment, and m2 is the sample variance.
is the sample mean, m3 is the sample third central moment, and m2 is the sample variance.
Given samples from a population, the equation for the sample skewness 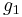 above is a biased estimator of the population skewness. (Note that for a discrete distribution the sample skewness may be undefined (0/0), so its expected value will be undefined.) The usual estimator of population skewness is
above is a biased estimator of the population skewness. (Note that for a discrete distribution the sample skewness may be undefined (0/0), so its expected value will be undefined.) The usual estimator of population skewness is
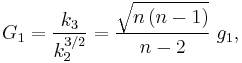
where 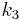 is the unique symmetric unbiased estimator of the third cumulant and
is the unique symmetric unbiased estimator of the third cumulant and 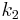 is the symmetric unbiased estimator of the second cumulant. Unfortunately
is the symmetric unbiased estimator of the second cumulant. Unfortunately 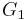 is, nevertheless, generally biased (although it obviously has the correct expected value of zero for a symmetric distribution). Its expected value can even have the opposite sign from the true skewness. For instance a mixed distribution consisting of very thin Gaussians centred at −99, 0.5, and 2 with weights 0.01, 0.66, and 0.33 has a skewness of about −9.77, but in a sample of 3, has an expected value of about 0.32, since usually all three samples are in the positive-valued part of the distribution, which is skewed the other way.
is, nevertheless, generally biased (although it obviously has the correct expected value of zero for a symmetric distribution). Its expected value can even have the opposite sign from the true skewness. For instance a mixed distribution consisting of very thin Gaussians centred at −99, 0.5, and 2 with weights 0.01, 0.66, and 0.33 has a skewness of about −9.77, but in a sample of 3, has an expected value of about 0.32, since usually all three samples are in the positive-valued part of the distribution, which is skewed the other way.
Properties
Skewness can be infinite, as when
![\Pr \left[ X > x \right]=x^{-3}\mbox{ for }x>1,\ \Pr[X<1]=0](/2012-wikipedia_en_all_nopic_01_2012/I/ddf47aee9002959302c25e2b7b67640f.png)
or undefined, as when
![\Pr[X<x]=(1-x)^{-3}/2\mbox{ for negative }x\mbox{ and }\Pr[X>x]=(1%2Bx)^{-3}/2\mbox{ for positive }x.](/2012-wikipedia_en_all_nopic_01_2012/I/7b6c6aab79a6804d6a8474f8cc3d0761.png)
In this latter example, the third cumulant is undefined. One can also have distributions such as
![\Pr \left[ X > x \right]=x^{-2}\mbox{ for }x>1,\ \Pr[X<1]=0](/2012-wikipedia_en_all_nopic_01_2012/I/e7b1a6cd4c343ff7b40ddd063d98acb8.png)
where both the second and third cumulants are infinite, so the skewness is again undefined.
If Y is the sum of n independent and identically distributed random variables, all with the distribution of X, then the third cumulant of Y is n times that of X and the second cumulant of Y is n times that of X, so ![\mbox{Skew}[Y] = \mbox{Skew}[X]/\sqrt{n}](/2012-wikipedia_en_all_nopic_01_2012/I/d937ed361411562bcc2311fbcfe34588.png) . This shows that the skewness of the sum is smaller, as it approaches a Gaussian distribution in accordance with the central limit theorem.
. This shows that the skewness of the sum is smaller, as it approaches a Gaussian distribution in accordance with the central limit theorem.
Applications
Skewness has benefits in many areas. Many models assume normal distribution; i.e., data are symmetric about the mean. The normal distribution has a skewness of zero. But in reality, data points may not be perfectly symmetric. So, an understanding of the skewness of the dataset indicates whether deviations from the mean are going to be positive or negative.
D'Agostino's K-squared test is a goodness-of-fit normality test based on sample skewness and sample kurtosis.
Other measures of skewness
Pearson's skewness coefficients
Karl Pearson suggested simpler calculations as a measure of skewness:[3] the Pearson mode or first skewness coefficient,[4] defined by
- (mean − mode) / standard deviation,
as well as Pearson's median or second skewness coefficient,[5] defined by
- 3 (mean − median) / standard deviation.
Starting from a standard cumulant expansion around a Normal distribution, one can actually show that skewness = 6 (mean − median) / standard deviation ( 1 + kurtosis / 8) + O(skewness2). One should keep in mind that above given equalities often don't hold even approximately and these empirical formulas are abandoned nowadays. There is no guarantee that these will be the same sign as each other or as the ordinary definition of skewness.
Quantile based measures
A skewness function
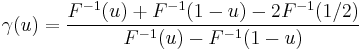
can be defined,[6][7] where F is the cumulative distribution function. This leads to a corresponding overall measure of skewness defined as the supremum of this over the range 1/2≤u<1,[6] while another measure can be obtained by integrating the numerator and denominator of this expression.[8] Galton's measure of skewness is γ(u) evaluated at u=3/4,[9] while other names for this same quantity are "Bowley Skewness",[10] "Yule-Kendall index"[11] and "quartile skewness". The function γ(u) satifies -1≤γ(u)≤1, and is well-defined without requiring the existence of any moments of the distribution.[8]
L-moments
Use of L-moments in place of moments provides a measure of skewness known as the L-skewness.
Cyhelský's skewness coefficient
A simple skewness coefficient derived from the sample mean and individual observations:
- a = ( number of observations below the mean - number of observations above the mean ) / total number of observations[12]
The skewness coefficient a approaches to normal distribution. If data set has at least 45 values then a is nearly normal. Distribution of a if data are taken from normal or uniform distribution is the same. Behavior of a in other distributions is currently unknown. Although this measure is very easy to understand, analytic approach is difficult.
Distance skewness
A value of skewness equal to zero does not imply that the probability distribution is symmetric. Thus there is a need for another measure of asymmetry which has this property: such a measure was introduced in 2000.[13] It is called distance skewness and denoted by dSkew. If X is a random variable which takes values in the d-dimensional Euclidean space, X has finite expectation, X' is an independent identically distributed copy of X and  denotes the norm in the Euclidean space then a simple measure of asymmetry is
denotes the norm in the Euclidean space then a simple measure of asymmetry is
- dSkew (X) := 1 - E||X-X'|| / E||X + X'|| if X is not 0 with probability one,
and dSkew (X):= 1 for X = 0 (with probability 1). Distance skewness is always between 0 and 1, equals 0 if and only if X is diagonally symmetric (X and -X has the same probability distribution) and equals 1 if and only if X is a nonzero constant with probability one.[14] Thus there is a simple consistent statistical test of diagonal symmetry based on the sample distance skewness:
- dSkewn(X):= 1- ∑i,j ||xi – xj|| / ∑i,j||xi + xj||.
See also
Notes
- ^ a b Susan Dean, Barbara Illowsky "Descriptive Statistics: Skewness and the Mean, Median, and Mode", Connexions website
- ^ von Hippel, Paul T. (2005). "Mean, Median, and Skew: Correcting a Textbook Rule". Journal of Statistics Education 13 (2). http://www.amstat.org/publications/jse/v13n2/vonhippel.html.
- ^ http://www.stat.upd.edu.ph/s114%20cnotes%20fcapistrano/Chapter%2010.pdf
- ^ Weisstein, Eric W., "Pearson Mode Skewness" from MathWorld.
- ^ Weisstein, Eric W., "Pearson's skewness coefficients" from MathWorld.
- ^ a b MacGillivray (1992)
- ^ Hinkley, D.V. (1975) "On power transformations to symmetry", Biometrika, 62, 101–111
- ^ a b Groeneveld (1984)
- ^ Johnson et al. (1994) pages 3, 40
- ^ Kenney, J. F. and Keeping, E. S. (1962) Mathematics of Statistics, Pt. 1, 3rd ed., Van Nostrand, (page 102)
- ^ Wilks,D.S (1995) Statistical Methods in the Atmospheric Sciences, Academic Press. ISBN 0-12-751965-3 (page 27)
- ^ "Statistické charakteristiky (míry)" (in Czech). Technical University of Liberec. p. 6. http://alnus.kin.tul.cz/~atm/upload/files/popisne_charakteristiky_2.pdf. Retrieved 3 July 2010.
- ^ Szekely, G.J. (2000). "Pre-limit and post-limit theorems for statistics", In: Statistics for the 21st Century (eds. C. R. Rao and G. J. Szekely), Dekker, New York, pp. 411-422.
- ^ Szekely, G.J. and Mori, T.F. (2001) "A characteristic measure of asymmetry and its application for testing diagonal symmetry", Communications in Statistics: Theory and Methods 30/8&9, 1633–1639.
References
- Groeneveld, RA; Meeden, G. (1984). "Measuring Skewness and Kurtosis". The Statistician 33 (4): 391–399. doi:10.2307/2987742. JSTOR 2987742.
- Johnson, NL, Kotz, S, Balakrishnan N (1994) Continuous Univariate Distributions, Vol 1, 2nd Edition Wiley ISBN0-471-58495-9
- MacGillivray, HL (1992). "Shape properties of the g- and h- and Johnson families". Comm. Statistics - Theory and Methods 21: 1244–1250.
External links
- An Asymmetry Coefficient for Multivariate Distributions by Michel Petitjean
- On More Robust Estimation of Skewness and Kurtosis Comparison of skew estimators by Kim and White.
- Closed-skew Distributions - Simulation, Inversion and Parameter Estimation
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||